什么是布隆过滤器
什么是布隆过滤器
布隆过滤器(Bloom Filter) 是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
简单来说是用于快速判断一个元素是否存在于一个集合中。具体来说,布隆过滤器包含一个位数组和一组哈希函数。位数组的初始值全部置为 0。在插入一个元素时,将该元素经过多个哈希函数映射到位数组上的多个位置,并将这些位置的值置为 1。
1字节(Byte)= 8位(Bit)

在查询一个元素是否存在时,会将该元素经过多个哈希函数映射到位数组上的多个位置,如果所有位置的值都为 1,则认为元素存在;如果存在任一位置的值为 0,则认为元素不存在。
布隆过滤器的优点
- 支持海量数据场景下高效判断元素是否存在。
- 布隆过滤器存储空间小,并且节省空间,不存储数据本身,仅存储hash结果取模运算后的位标记。
- 不存储数据本身,比较适合某些保密场景。
布隆过滤器的缺点
- 不存储数据本身,所以只能添加但不可删除,因为删掉元素会导致误判率增加。
- 由于存在hash碰撞,匹配结果如果是“存在于过滤器中”,实际不一定存在。
- 当容量快满时,hash碰撞的概率变大,插入、查询的错误率也就随之增加了。
对布隆过滤器的一些理解
- 布隆过滤器要设置初始容量。容量设置越大,冲突几率越低。
- 布隆过滤器会设置预期的误判值。
布隆过滤器的误判是否可以接受?
布隆过滤器的误判是可以接受的,前提是你理解并接受其使用场景的特点和限制。
- 误判的影响
- 布隆过滤器可能会错误地报告某个元素存在,尽管实际上它并不存在。这种情况称为“假阳性”。
- 假阳性的概率与布隆过滤器的大小、哈希函数的数量以及存储的元素数量有关。通过合理的设计,这个误判概率可以被控制在一个较低的范围内。
- 可以接受的原因
- 空间效率:布隆过滤器在内存占用方面非常高效,特别适合大规模数据集合的判断场景。在内存资源有限的情况下,布隆过滤器能够大大减少存储需求。
- 查询速度:布隆过滤器的查询操作非常快速,通常只需要O(1)的时间复杂度,非常适合实时查询的场景。
- 适用场景:布隆过滤器被广泛应用于需要快速判断是否存在的场景,并且这些场景能够容忍一定的假阳性。例如,网络爬虫中用来过滤已经访问过的URL,数据库的缓存系统中用来判断数据是否在缓存中等。这些场景中,假阳性只会导致不必要的进一步检查,而不会造成致命的错误。
- 不适用的场景
- 需要绝对精确性的场景下,布隆过滤器的误判不可接受。例如,在金融交易、医疗数据处理、密码学等领域,误判可能导致严重的后果,因此不适合使用布隆过滤器。
- 如果误判会带来较大的系统开销或业务逻辑复杂性增加,那么也需要谨慎选择是否使用布隆过滤器。
就拿用户注册来说,布隆过滤器的误判我们可以接受吗?
可以接受。为什么?因为用户名不是特别重要的数据,如果说我设置用户名为 test,系统返回我不可用,那我大可以在 test 的基础上再加一个 666,也就是 test666。
布隆过滤器的使用场景
- 解决Redis缓存穿透问题
- 邮件过滤,使用布隆过滤器来做邮件黑名单过滤
- 对爬虫网址进行过滤,爬过的不再爬
- 海量用户同时注册打满数据库情况
- 解决新闻推荐过的不再推荐(类似抖音刷过的往下滑动不再刷到)
布隆过滤器原理
BloomFilter 的算法是,首先分配一块内存空间做 bit 数组,数组的 bit 位初始值全部设为 0。
加入元素时,采用 k 个相互独立的 Hash 函数计算,然后将元素 Hash 映射的 K 个位置全部设置为 1。
检测 key 是否存在,仍然用这 k 个 Hash 函数计算出 k 个位置,如果位置全部为 1,则表明 key 存在,否则不存在。
 哈希函数 会出现碰撞,所以布隆过滤器会存在误判。
哈希函数 会出现碰撞,所以布隆过滤器会存在误判。
这里的误判率是指,BloomFilter 判断某个 key 存在,但它实际不存在的概率,因为它存的是 key 的 Hash 值,而非 key 的值。
所以有概率存在这样的 key,它们内容不同,但多次 Hash 后的 Hash 值都相同。
代码中使用布隆过滤器
引入Redisson依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
</dependency>
配置Redis参数
spring:
data:
redis:
host: 127.0.0.1
port: 6379
password: 123456
创建布隆过滤器实例
@Configuration
public class RBloomFilterConfiguration {
/**
* 防止用户注册查询数据库的布隆过滤器
*/
@Bean
public RBloomFilter<String> userRegisterCachePenetrationBloomFilter(RedissonClient redissonClient) {
RBloomFilter<String> cachePenetrationBloomFilter = redissonClient.getBloomFilter("userRegisterCachePenetrationBloomFilter");
cachePenetrationBloomFilter.tryInit(100000000, 0.001);
return cachePenetrationBloomFilter;
}
}
tryInit 有两个核心参数:
- expectedInsertions:预估布隆过滤器存储的元素长度。
- falseProbability:运行的误判率。
错误率越低,位数组越长,布隆过滤器的内存占用越大。
错误率越低,散列 Hash 函数越多,计算耗时较长。
我们可以通过这个在线网站进行占用内存大小对比。
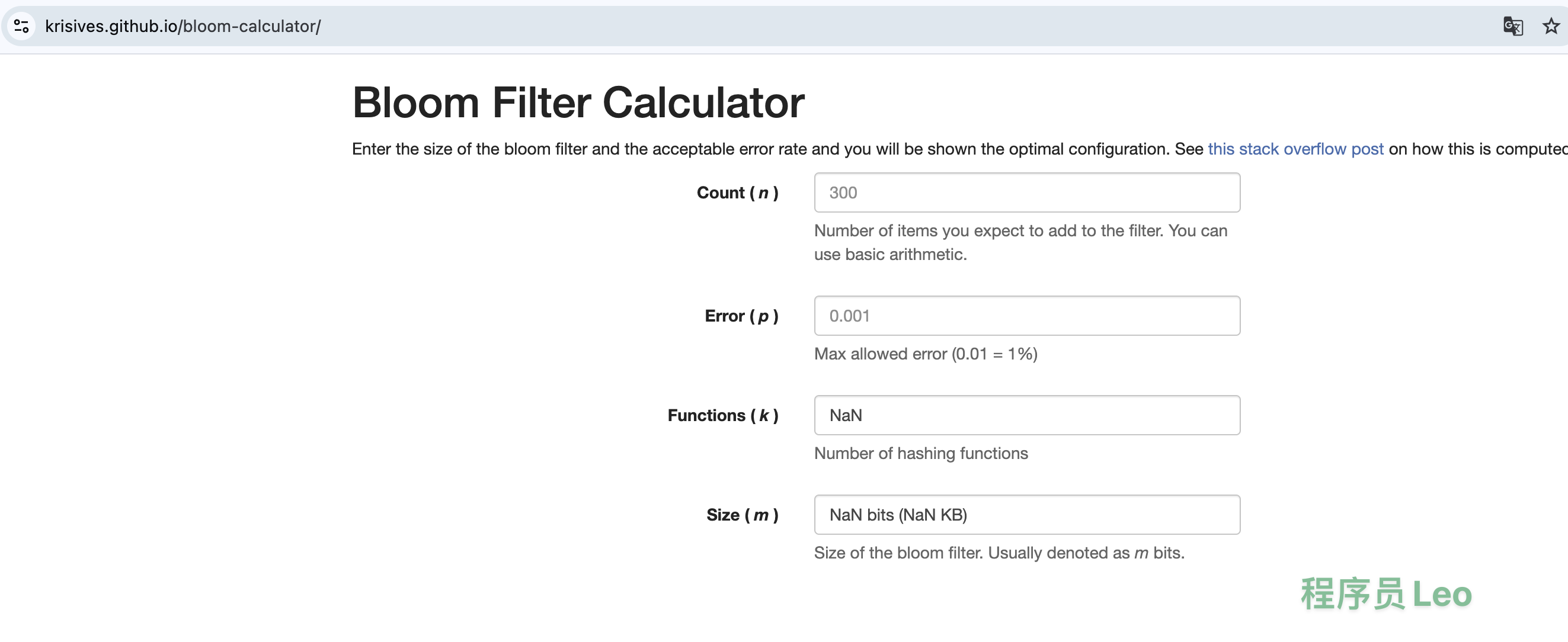
使用布隆过滤器的两种场景:
我们这里依然以用户注册为例
- 初始使用:注册用户时就向容器中新增数据,就不需要任务向容器存储数据了。
- 使用过程中引入:读取数据源将目标数据刷到布隆过滤器。
在代码中引入
@Service
@RequiredArgsConstructor
public class UserServiceImpl extends ServiceImpl<UserMapper, UserDO> implements UserService {
private final RBloomFilter<String> userRegisterCachePenetrationBloomFilter;
private final RedissonClient redissonClient;
/**
* 判断用户名是否存在
*
* @param username 用户名
* @return true:存在;false:不存在
*/
@Override
public Boolean hasUsername(String username) {
return userRegisterCachePenetrationBloomFilter.contains(username);
}
/**
* 注册用户
*
* @param requestParam 用户注册请求参数
*/
@Override
public void register(UserRegisterReqDTO requestParam) {
// 判断用户名是否存在
if (hasUsername(requestParam.getUsername())) {
throw new ClientException(UserErrorCodeEnum.USER_NAME__EXIST);
}
// 获取分布式锁
RLock lock = redissonClient.getLock(LOCK_USER_REGISTER_KEY + requestParam.getUsername());
try {
if (lock.tryLock()) {
// 保存用户信息
UserDO userDO = BeanUtil.convert(requestParam, UserDO.class);
int insert = baseMapper.insert(userDO);
if (insert != 1) {
throw new ClientException(UserErrorCodeEnum.USER_SAVE_ERROR);
}
// 加入布隆过滤器
userRegisterCachePenetrationBloomFilter.add(requestParam.getUsername());
return;
}
throw new ClientException(UserErrorCodeEnum.USER_NAME__EXIST);
} finally {
lock.unlock();
}
}
}
注意: 这里有一个问题,当我们注册用户的时候,需要先通过布隆过滤器进行验证用户名是否存在,测试布隆过滤器中是没有添加用户名的,只有当我们将这个用户注册成功之后才会把用户添加到布隆过滤器中,所以这里会报异常。
结局方案:
我这里的做法是初始化初始化布隆过滤器
@Slf4j
@Component
@RequiredArgsConstructor
public class BloomFilterInitializer implements ApplicationRunner {
private final UserMapper userMapper;
private final RBloomFilter<String> userRegisterCachePenetrationBloomFilter;
@Override
public void run(ApplicationArguments args) throws Exception {
log.info("开始加载数据库中的用户名到布隆过滤器...");
List<String> allUsernames = userMapper.getAllUsernames();
allUsernames.forEach(userRegisterCachePenetrationBloomFilter::add);
log.info("加载完成,共计{}个用户名", allUsernames.size());
}
}
在系统启动时,将数据库中的所有用户名加载到布隆过滤器中。通过快速判断用户名是否存在来减少不必要的数据库查询。整个过程通过Spring的 ApplicationRunner 接口在应用启动时自动触发。
大功告成!
其他几个功能注意点
如何防止用户名重复?
- 缓存策略:将已有的用户名缓存到Redis中,在新用户注册时,先查询Redis缓存。如果用户名存在于缓存中,直接返回错误;如果不存在,再进行数据库检查和更新。
- 布隆过滤器:结合布隆过滤器可以减少不必要的数据库查询,但最终还是需要数据库检查来保证唯一性。
通过布隆过滤器把所有用户名进行加载。这样该功能就能完全隔离数据库。然后在数据库层面添加唯一索引作为兜底。
如何防止恶意请求毫秒级触发大量请求去一个未注册的用户名?
因为用户名没注册,所以布隆过滤器不存在,代表着可以触发注册流程插入数据库。但是如果恶意请求短时间海量请求,这些请求都会落到数据库,造成数据库访问压力。这里通过分布式锁,锁定用户名进行串行执行,防止恶意请求利用未注册用户名将请求打到数据库。
这里依旧以用户注册为例,使用布隆过滤器 + 分布式锁实现。
@Override
public void register(UserRegisterReqDTO requestParam) {
// 判断用户名是否存在
if (hasUsername(requestParam.getUsername())) {
throw new ClientException(UserErrorCodeEnum.USER_NAME__EXIST);
}
// 获取分布式锁
RLock lock = redissonClient.getLock(LOCK_USER_REGISTER_KEY + requestParam.getUsername());
try {
if (lock.tryLock()) {
// 保存用户信息
UserDO userDO = BeanUtil.convert(requestParam, UserDO.class);
int insert = baseMapper.insert(userDO);
if (insert != 1) {
throw new ClientException(UserErrorCodeEnum.USER_SAVE_ERROR);
}
// 加入布隆过滤器
userRegisterCachePenetrationBloomFilter.add(requestParam.getUsername());
return;
}
throw new ClientException(UserErrorCodeEnum.USER_NAME__EXIST);
} finally {
lock.unlock();
}
}
}
下面简述具体步骤:
步骤 1:检查布隆过滤器
- 当一个注册请求到达时,首先通过布隆过滤器检查用户名是否存在。
- 如果布隆过滤器判断用户名不存在,继续进入下一步。
- 如果布隆过滤器判断用户名存在(即用户名可能已经注册),需要进一步确认数据库中的实际情况。
步骤 2:获取分布式锁
- 针对每个注册请求,获取基于用户名的分布式锁,确保同一时间只有一个请求能够处理该用户名的注册。
- 如果锁获取失败(即该用户名正在被其他请求处理),可以返回一个提示信息或等待再重试。
步骤 3:数据库验证
- 在成功获取锁后,再次从数据库中确认用户名是否已存在。此步骤是为了处理并发情况下,布隆过滤器的假阳性问题。
- 如果用户名已经存在,抛出异常,提示用户名已存在。
- 如果用户名不存在,则进行用户数据的插入操作。
步骤 4:释放锁
- 无论注册操作成功与否,都要确保在
finally块中释放分布式锁,防止死锁的情况发生。
如果恶意请求全部使用未注册的用户名发起注册该怎么办?
结论:系统无法进行完全风控,只有通过类似于限流的功能进行保障系统安全。
如果恶意请求全部使用已经注册的用户名发起注册请求,这种情况可能会导致系统频繁地进行数据库查询、锁定和资源消耗。
当然我们可以通过其他手段对我们的服务端进行防护:
1. 速率限制(Rate Limiting)
- 对于同一用户名或同一IP的注册请求,设置速率限制。每个用户名在一定时间内只能发起有限次数的注册请求,一旦超过限制,系统可以返回错误或阻止请求。
- 可以使用工具如
RateLimiter、Nginx 的limit_req模块,或在 API 网关层实现速率限制。
2. 使用Sentinal进行限流
Sentinel 提供了多种限流策略,可以精确控制流量:
- 固定窗口限流:按照固定的时间窗口限制流量,比如每秒允许的最大请求数。
- 滑动窗口限流:基于滑动窗口的限流策略,更平滑地处理流量。
- 漏桶算法:确保请求以固定速率处理,避免突发流量的影响。
- 令牌桶算法:允许在短时间内处理突发流量,但限制长期的请求速率。
3. 分布式缓存检查
在布隆过滤器的基础上,可以结合分布式缓存(如 Redis),在内存中缓存最近频繁访问的用户名。对于这些用户名,系统可以快速响应,不进行重复的数据库查询。